作者 | 聂镭 来源 | 零壹智库
谷歌上演了一出“那些没有杀死我的,将使我更强大”。
互联网高速发展了几十年,但全世界超过10亿用户的业务或者应用一共没超过20个,而谷歌拥有6个。在绝大很多网民心目中,Google是人类历史上最伟大的公司,没有之一,而且在人工智能方面的先发优势不可撼动。
这一信念嘎然而止在2022年11月20号ChatGPT发布的历史性时刻,众人纷纷倒向新观点“像ChatGPT这样的人工智能聊天机器人将像搜索引擎杀死黄页一样摧毁谷歌”(Gmail的创始人Paul Buchheit语)。谷歌Bard发布当天,市值下跌千亿美金,似乎正好印证了这个论断。
但Gemini的发布惊艳世人,改变了大模型领域ChatGPT独领风骚的局面。
Gemini不仅在很多性能上超过了ChatGPT 4,它同时带来了另一种可能性:具有原生数据优势的互联网巨头,可能在多模态大模型竞争中占据优势。这意味着,谷歌、马斯克、Meta以及中国的腾讯、抖音、阿里、百度等公司都有可能在Gemini开创的路线上加速迭代大模型。
大模型战局,进入第二阶段。第一阶段只用一年时间,就搅翻了整个全球互联网和人工智能,在摩尔定律的加持下,第二个阶段,又将是怎样突破人类的想象力?
01
史诗级的一年
从2022年11月20号ChatGPT发布之后这一年,几乎日日充斥“奇点时刻”的惊爆与“AI下半场”的狂欢,GPTs和GPT4 Turbo也意料之外情理之中地发布了。还有一系列Sam Altman作为CEO被OpenAI董事会开除、又王者归来的桥段出现,吃瓜群众应接不暇。
然而即便是在这样的乱世里,由Google+DeepMind用尽洪荒之力推出的AGI里程碑“双子星Gemini”发布仍然可以算是核弹级的。为什么?不妨让从资本市场这个最敏感的仪表盘看看大模型的史诗级影响:
1、投资OpenAI百亿美金的大赢家微软市值大涨50%来到3万亿美元,无疑成AI最大受益者。
2、大模型淘金热的万卡起步,让英伟达股价飙升了245%,市值解锁万亿后停不下来,已突破1.2万亿美元,超过Facebook母公司Meta或特斯拉,跻身所谓“七巨头”。
3、作为登上巅峰后迄今为止在互联网搜索领域的完全统治地位的Google,这一年天天度日如年,这一年内讨论Google被颠覆话题占有史以来的99%以上,如果谷歌输掉这场AI之战会怎么样?二级市场已经给出了回答。Bard发布当天的一次回答错误,就让Google母公司Alphabet市值减少了1000亿美元。
然而就在上周ChatGPT一周年庆之后,Google高调发布“史上功能最强的通用人工智能大模型”,据称通过大型语言模型领域中广泛使用的32个基准测试,几乎全部(其中30个)表现出了“最先进的性能”,不仅击败了OpenAI的GPT-4,甚至在MMLU(大规模多任务语言理解)基准测试中,成为第一个超越人类专家的模型。
如果这是真的,意味着什么?“这巨大飞跃将影响几乎所有的Google产品。”要知道Google是(至少目前还是)全球最大的互联网公司、搜索引擎的绝对霸主,而搜索无处不在,仍是绝大多数人获取信息的第一方式;Google母公司Alphabet的名字也说明了它的产品布局是无孔不入的。
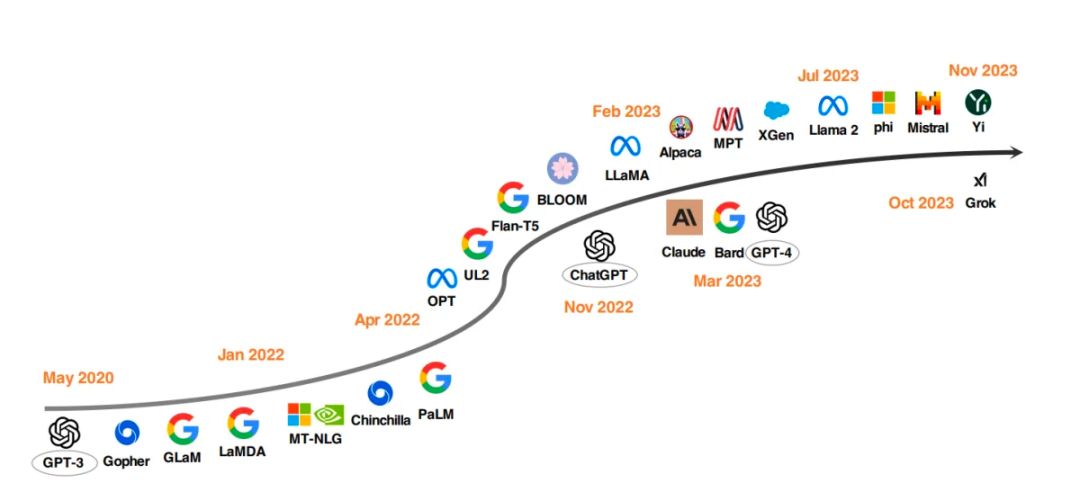
2020年GPT-3以来的标志性大模型产品
02
谷歌的洪荒之力
那么,姗姗来迟的Google AGI,Gemini,究竟有没有力挽狂澜的底气?
实际上,Gemini项目需溯源至2023年4月20日,是Google吹响了“红色警报”之后的关键战略抉择。那天,谷歌选择将Google Brain与DeepMind合并,成立了Google DeepMind,并宣布将公司在AI领域的世界级人才、计算能力及TPU基础设施等资源加以结合,创新研发大模型以对标OpenAI的GPT-4,可谓押上了全部赌注,殊死背水一战。
“Gemini是Google的下一代多模态大模型”的战书已下,让外界对Gemini关注度持续升高、好奇心拉满。7月,辞职已有四年的谷歌联合创始人Sergey Brin(谢尔盖・布林)重返谷歌,其回归无疑是助阵Gemini系统,也让业界预感“Gemini将会是下半年大模型赛道的焦点。”
Gemini特征有如下三个:
1、原生多模态、多语言多国度、从海量云存储数据中做预训练
在谷歌给出的长达60页的Gemini技术报告中,最值得关注的是,Gemini模型的训练数据集既多模态又多语言。其中,前期训练数据集使用来自网络文档、书籍和代码的数据,包括图像、音频和视频数据等。
“Google拿自家海量云存储的图片进行了预训练,确实把模型的多模态能力拉升了一大截。”谷歌在Gemini技术报告中写到,“当模型多模态能力被真正探索出来时,会提供更多细节。”
实际搭载Gemini Pro的Bard与GPT-4进行的对比测试表明:通过识别不同图片中的人物、地点、文字、动物甚至其中可能蕴含的科学知识,综合对比,Gemini Pro的多模态能力确实足以抗衡GPT-4,前者的响应速度也“快很多”,另外,前者可以免费使用,但后者已经有了“3小时40次的限制”。
2、多尺寸、分场景,发挥Google布局生态优势
Gemini分Ultra、Pro和Nano三种不同尺寸和万能应用场景的设计,其中Ultra版可用于大型数据中心等,属于处理高复杂度任务的模型;Pro版则用于各种扩展任务,属于日常使用模型,且已搭载于谷歌的对话机器人Bard中;Nano版则是应用于智能手机等移动设备终端上的模型。
Google在多年的布局中,早就通过收购拥有了TPU计算集群、YouTube内容入口、Andriod移动操作系统等无处不在的生态优势,若Gimini能堪与GPT-4在AGI能力上“掰手腕”的大任,那么胜负的天平无疑将反过来倒向守成者Google一边
3、人海战术
前面提及长达60页的Gemini技术报告,最令其惊讶的是光报告的作者就多达9页,“每页90人,八百余人,超过OpenAI公司的总人数。”
要知道,OpenAI员工总数目前不足800人,虽然在AI人才争夺战中OpenAI虹吸了不少来自各个巨头AI部门的大咖,当然Google Brain和Deepmind也不会幸免,在其中贡献了最大比例。
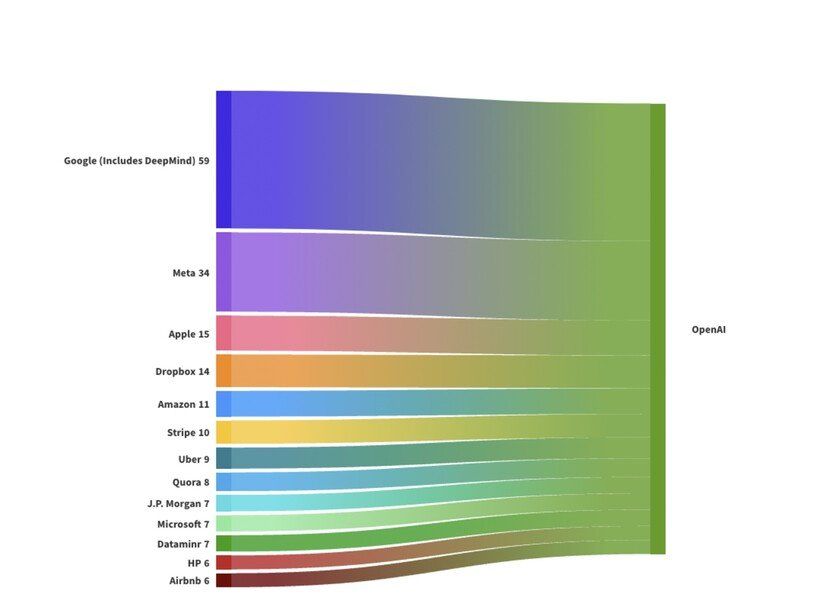
OpenAI人才来源
数据统计来自Leadgenious Punks&Pinstripes
但即便如此,瘦死的骆驼比马大,Google Brain内部仍然人才济济,仍然有超过800位以上来自世界各地的顶尖科学家;DeepMind目前拥有大约1000名员工,而且高薪养人,平均每名员工工资接近47万英镑,相当于人民币400万。
两者合并得到Gemini,这也不难看出谷歌在Gemini模型开发与技术创新方面投入的AI人才之多。更何况Google毕竟是一个拥有将近20万员工的巨无霸,AI巅峰之战提到最高议事日程上以后,内部优势兵力一定会向主战场汇集。
03
Gemini带来的,是“路线之争”
但这是否表明Gemini的发布已经形势占优,甚至对GPT-4形成了“全面超越”?由于目前还无法完成全面的测评,只能为大家提供以下重要参考:
1、Gemini在中文识别理解能力上,相较GPT-4略逊一筹,也就是说“Gemini仍无法可靠处理‘非英语’的任务。”
2、谷歌专门针对测试相关领域进行了优化,Gemini只在既定领域中的指标表现好,并不能够说明模型真正的泛化能力强。“至于真正能力,需要在更多的数据集上进行测评。”
演示视频被质疑夸大造假,而且是用尚未发布的Ultra而不是可测的Pro版本,一时间招致很多抨击,风波不断,但旋即谷歌也甩出演示视频制作的记录文章,大方承认视频经过剪辑合成。原来,在专业提示词循循善诱的前提下才调度到的多模态推理能力,这多少有些“强力粉饰”的魔术效果和心理暗示,但多模态的基础推理能力还是确实在的。
由此可见与ChatGPT巅峰对决的难度之大!连昔日AI绝对王者也需要做对公众先做这样的心理诱导,等不及产品的完整实用化~



如图:发布视频中只保留了模型输出的反馈,没有充分暴露提示
3、原生多模态训练的范式经验证能走通,那么新的训练范式的上限极高,这条技术路线将吸引大多数拥有内容数据的平台型企业追随。Google产品线积累的海量高质量多模态数据,是后续Gemini的快速、持续迭代的保障。
Gemini的技术报告中也有这样一段表述,“谷歌发现数据质量对于高性能模型至关重要,并认为在寻找预训练的最佳数据集分布方面,仍有许多有趣的问题。”
为拓展多模态模型的训练数据集,谷歌还对外表示,Bard将在超过170个国家和地区提供Gemini Pro版本服务,并计划未来扩展到不同的模态,支持更多语言和地区。
不仅明年初将推出升级的Bard Advanced版本,在接下来的几个月里,谷歌还将陆续把Gemini应用于搜索、广告、Chrome等更多的产品和服务中。
04
新战局开始了
ChatGPT一骑绝尘的情况下,其他选手本已望尘莫及,Gemini的发布让人看到了未来世界风云变幻的一种现实可能性,就是从数据优势出发,走原生多模态技术路线。
而这一新赛道(如果将来成功翻盘就算是新的)也将必然成为在互联网领域原来已经深耕多年、有数据优势的大厂之必选。
谷歌之外,Meta拥有全球30亿用户,它的大模型Llama在下一战局中不可小觑;而中国的腾讯、阿里、抖音、百度等互联网巨头都是拥有10亿级用户的大厂,并且都在发布了自己的大模型。
至于下阶段哪家率先宣布也有了原生多模态的竞争力,需拭目以待。
不过要说每一家有江湖名号的都重新获得追赶甚至超越的机会,那得看“硬核”马斯克(Elon Musk)同不同意。现在,他已经拥有了庞大的原生数据来源。
作为实干冒险家,马斯克向来生死看淡、不服就干。他曾天使投资OpenAI一亿美金,想以特斯拉吸收OpenAI被拒,最终被踢出局。马斯克可谓初恋爱之深、未婚恨之切,携数据优势与宇宙情怀重新杀回AI争霸之路――X改名自马斯克四百亿美金买回来的Twitter,xAI于今年7月12日官宣成立。
马斯克是一个把太多不可能变成现实的人,他以“X”入道肩负起“为全人类发展的希望,了解宇宙的真实本质,确保人工智能的发展有助于人类意识的持久发展”。
xAI在通过X平台实时了解世界方面具有独特而根本的优势,且能够回答其他人工智能系统拒绝回答的尖锐问题,这源于其设计初衷是通过智慧和一些叛逆的倾向来回答问题,“如果您不喜欢幽默,请不要使用它。”果然骨骼惊奇,非常马斯克。
更重要的是,马斯克的拥有庞大的原生数据来源:从推特改名而来的X(与xAI几乎同名),全球特斯拉数据,以及星链可能带来的庞大数据。
前几个月出版的《埃隆・马斯克传》写道:
“喂养人工智能,靠的是数据。新诞生的这些聊天机器人正在接受海量信息的训练,包括互联网上的数十亿个网页和其他文档。谷歌和微软拥有搜索引擎、云服务和电子邮箱,他们手头有大量的数据可以帮他们训练这些系统。”
“马斯克能给这场战局带来什么呢?马斯克坐拥的一大数据资产是推特的信息流,其中包括多年来所有人发布的超过1万亿条推文,还有每天新增的5亿条。它是人类集体意识的体现,是世界上更新最及时的数据集,包含了现实生活中人类的各种对话、新闻、兴趣、趋势、争论和术语。”
“此外,它还是一个很好的训练场,可以让聊天机器人测试真人对其回复做出的反应。马斯克在收购推特时并没有考虑到这些数据的价值,他说:‘实际上这算是一个附带的好处,我是在买下推特以后才意识到的。’”
“马斯克还拥有另一个数据宝库:特斯拉每天从自家车辆上的摄像头接收并处理的1 600亿帧视频画面。这些数据不同于为聊天机器提供信息的文本文件,这是人类在真实世界中导航的视频数据,它有助于为实体机器人打造人工智能系统,而不再是只能?成文本的聊天机器人。”
“通用人工智能的王冠是打造出能够像人类?样在物理空间(比如工厂、办公室和火星表面)运行的机器,而不仅是?些让我们感到惊艳的虚拟聊天机器人。特斯拉和推特可以共同为这两个研究方向提供数据集和数据处理能力:不管是教机器在物理空间中自主导航,还是教它们用自然语言回答问题。”
2023年1月,马斯克在推特会议室召开了一系列深夜会议,研究如何针对这项服务收费的问题。他认为这是一个将推特数据集变现的好机会。且能限制谷歌和微软使用这些数据改进自家的人工智能聊天机器人。
我们可以脑补一下,如果这些具有庞大原生数据的大厂在竞争中采用数据收费甚至数据垄断策略,下一阶段的战况,将会怎样?!
Google王者业已归来,Gemini出场花式秀魔术引发全员关注和质疑争论,但宣传目的已经基本达到了,并就此掀起大模型战局的新篇章。
毫无疑问,大模型PK精彩程度将愈演愈烈。在这个每72小时就必有大事件的时代,请紧跟了别掉队,一起洞见未来~
(作者聂镭,龙马智芯创始人,零壹智库特约专家,国防科技大学人工智能博士、副研究员,广东省领军人才)